
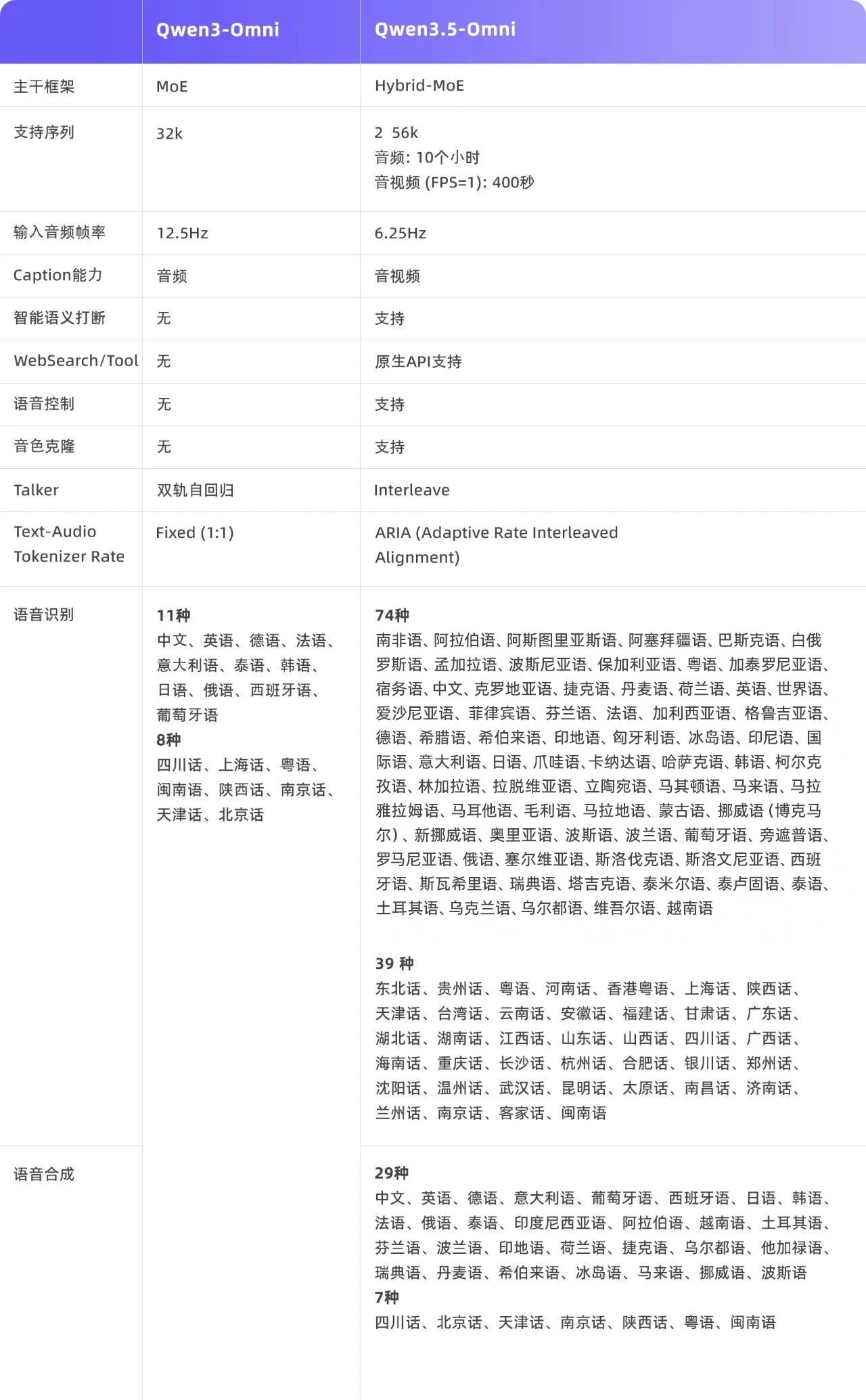
IT之家 3 月 30 日消息,阿里千问今晚发布全模态大模型 Qwen3。
无缝理解文本、图片、音频及音视频输入,支持细粒度、带时间戳的音视频 Caption 生成。
215 项 SOTA 霸榜,在音频及音视频分析、推理、对话、翻译等任务超过 Gemini3。
自然涌现的 Audio-Visual Vibe Coding 能力。
支持语义打断、音色克隆及语音控制,让对话体验更自然。
5-Omni-Plus 能够遵循指令生成细粒度,结构化,带时间戳的准确 Caption:画面里是谁、说了什么话、背景音乐从哪一秒开始变化、镜头切了几次、每一帧发生了什么。
来源:IT之家










