临时 GPU 上的自主 RL 微调:使用 autoresearch-rl 扩展 Karpathy 的自动研究 自主 ML 研究的困难部分不是搜索算法。
Covenant Labs 和 Evangelos Pappas 2026 年 3 月 27 日 5 分享 当 Karpathy 发布 autoresearch [1] 时,他向 LLM 展示了您可以向 LLM 提供训练脚本,让它提出更改建议,运行实验,观察结果,然后重复。
相同的 GPU、相同的环境、几分钟内的迭代。
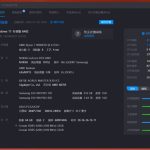
我想测试一个更难的主张:相同的循环是否可以用于 RL 微调,其中每次迭代都需要自己的 GPU,奖励稀疏,并且单个错误的超参数会浪费一个小时的 A100 时间。
答案是肯定的,但困难的部分并不是我想象的那样。
一条命令: uv run autoresearch-rlexperiment。
来源:HackerNews New